Gestión de la Configuración
Resumen ejecutivo
La intención de este documento es la de registrar todos los procedimientos de la organización para llevar a cabo un desarrollo del proyecto organizado y unificado.
Introducción a la Configuración del Proyecto
AparKing es una aplicación de búsqueda de aparcamiento de manera rápida y sencilla destinada a ayudar a los conductores a estacionar su vehículo. Luego, siguiendo los requisitos establecidos por el cliente, el producto debe poseer las características de una Progressive Web App, por lo que se segmentará el código de la aplicación en frontend y backend, cada uno con tecnologías diferentes, Angular con Ionic y Django, respectivamente. Todo esto, se suma a los períodos de desarrollo ajustados. La organización ha decidido configurar el proyecto con los procedimientos descritos en los siguientes apartados del documento.
Tecnologías y Convenciones Estilísticas
Es importante establecer unas convenciones estilísticas a la hora de escribir el código fuente, asegurando un código limpio y fácil de entender por todos los integrantes del equipo. Dividimos esta configuración en dos:
| Framework | Lenguaje | Guías de estilo | |
|---|---|---|---|
| Frontend | Angular v17 + Ionic 7.7.2 | JS ES23 + TS 5.3 | Google JS Style |
| Backend | Django 5.0 + Django RestFramework 3.14.0 | Python 3.12.2 | PEP8 1.7.1 |
Para preservar esta configuración, el entorno de desarrollo tendrá las siguientes características:
| Nombre de la característica | Nombre de la tecnología / convención |
|---|---|
| Sistema operativo | MacOS/Windows 10/11 o WSL |
| Entorno de desarrollo Integrado (IDE) | Visual Studio Code 2023/24 |
| Extensiones del IDE | Extensiones de Frontend: Angular Language Service, Angular Snippets (Version 16) e Ionic. Extensiones de Backend: Python Extension Pack. Extensiones de entorno: ESLint, Prettier, GitLens, Thunder Client, EditorConfig for VSCode, Path Intellisense, Auto Rename Tag, Auto Close Tag, WSL (opcional). |
| Idioma para el código del proyecto | Inglés |
Además, se hará uso de una herramienta de escaneo y corrección estilística llamada pre-commit que analiza el código antes de hacer commit, corrigiendo los archivos según las normas estilísticas.
Luego, en cuanto a la estructura de carpetas, se seguirán las estructuras convencionales de cada framework. Teniendo en Django una carpeta principal de configuración del sistema y una por cada módulo propio del back-end, además de los archivos de conjuración y arranque. Cabe mencionar que para poder hacer la integración de angular con Django tenemos que usar Django Rest Framework, para lo que hace falta añadir un archivo de serializers en cada app de Django. Luego, en Angular carpetas separadas por componentes, modelos, servicios y pages:
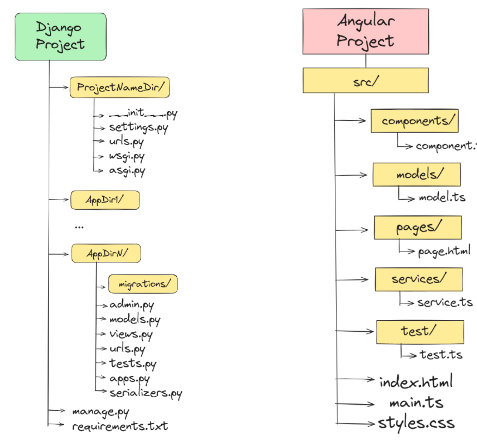
Por último, mencionar que, aunque en el desarrollo de la aplicación se utilizará la base de datos integrada de Django, SQLite3, debido a la dinamicidad que ofrece y que está pensada para apoyar en la fase de desarrollo. Una vez desarrollado el sistema, se hará una migración a una base de datos PostgreSQL 16.2 debido a que aporta diversas capas de seguridad y eficiencia que no trae consigo la versión “light” de SQLite3.
Patrones de Épicas, Issues y Gestión de Tareas
En este apartado se definirá la gestión de tareas y, por ende, la estructura que deberán seguir las épicas e issues durante la realización de nuestro proyecto. El objetivo de estos patrones es lograr establecer un marco conciso para todo el equipo.
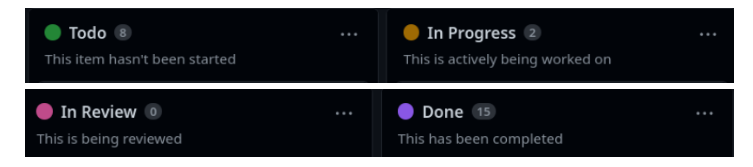
Para comenzar, la gestión de tareas de AparKing se realizará a través de los tableros de GitHub Projects, donde se nos permitirá poder clasificar cada épica e incidencia según su tamaño, urgencia y, especialmente, su estado en cuanto a progreso. Este es el proceso que se debe seguir en el tablero del proyecto:
Trabajo preliminar:
- Tomar una tarea del product backlog.
- Convertir la tarea en una issue de GitHub.
- Asignar la tarea a uno o más miembros del equipo para su realización.
- Colocar dentro de GitHub Projects la tarea en la columna de Product Backlog.
- Si correspondiese al sprint que esté tomando lugar durante ese momento, se mueve la tarea al Sprint Backlog.
Desarrollo:
- Mover la tarea a la columna de “In progress” cuando se comience a trabajar en ella.
- Crear una rama para esta tarea según las políticas de estrategia de ramificado explicadas en el apartado 3.4.
Proceso de revisión:
- Una vez esta tarea esté terminada, deberá ser revisada en su correspondiente pull request. Dicha operación debe crearse siguiendo los patrones de creación de esta, explicados después en el apartado 3.6.
- Mover la tarea a la columna de “In review” cuando el pull request esté listo para revisión.
- Asimismo, el proceso de revisión de los compañeros deberá seguir las normas establecidas en el apartado 3.5.
Finalización:
- Una vez la tarea haya sido revisada y aprobada, deberá moverse a la columna de “Done” del tablero, así como cerrar la issue o épica correspondiente.
Ejemplo de columnas del tablero de GitHub Projects:
Las tareas épicas representan grandes conjuntos de funcionalidades o características del proyecto. Se definen de forma general y están compuestas por un conjunto de issues. En cuanto a su creación, se seguirá el siguiente formato:
- Nombre: Opcionalmente se indicará que es una épica. Su nombre debe concisamente explicar qué abarca para que los participantes puedan tener una idea de cuáles issues incluiría fácilmente.
- Descripción: Opcionalmente se incluirá una descripción con detalles e información necesaria.
Por otro lado, las issues representan unidades de trabajo más pequeñas y específicas dentro de una épica. Deben ser tareas bien definidas y con un objetivo claro. Para crear una issues, seguiremos el siguiente formato:
- Nombre: Descripción breve y concisa de la tarea.
- Descripción: Opcionalmente se incluirá una descripción con detalles e información necesaria.
- Responsable: Asignación del responsable o responsables de la tarea. Asimismo, se deberá asignar la etiqueta del grupo correspondiente al que le pertenezca la tarea, pudiendo ser “g1”, “g2” o “g3”.
- Etiquetas: En caso de ser una epic, se le asignará la etiqueta “epic”. En cuanto a las issues, si se tratase de una nueva funcionalidad, se asignará “feat”; si fuese arreglos, “fix”; si fuese documentación, “doc”; si fuese configuración del entorno o proyecto, “conf”; si fuese tareas de despliegue, “deploy”; y si fuese refactorización del código, “refact”.
- Tamaño: Opcionalmente, a través de una etiqueta, se estimará el tamaño de la tarea
- Prioridad: Opcionalmente, a través de una etiqueta, se estimará la priorización de la tarea (alta, media, baja)
- Estimación de tiempo: El resultado de Planning Poker realizado durante la fase de planificación entre, o todos los participantes, o el grupo completo
Como hemos visto en la gestión de tareas a través de GitHub Projects, se clasificará el estado cada épica e issue a través de la columna en la que se encuentre.
Estrategias de ramificado
Para un mejor manejo del código hemos optado por implementar GitFlow. De este modo que disponemos de una rama principal la cual siempre será estable, Master, y otra también principal, pero en la que se implementarán todos los avances del progreso, Develop. Será desde esta última de la que se sacarán las ramas secundarias, cada una de estas representarán una funcionalidad nueva o “feature” en inglés. De tal forma, que la integración de dichos avances se podrá verificar en la rama develop antes de aplicar los cambios en la rama principal, master.
Una vez se hayan incorporado los cambios de las features en la rama principal, dicha rama de feature se eliminará para mantener un espacio de trabajo ordenado y limpio.
En caso de requerir de algún parche, ya sea por seguridad o error detectado en el código, dependiendo de la gravedad de este se creará una rama de HotFix que será mergeada directamente a master o develop.
El estándar a seguir para crear y nombrar las ramas será el siguiente:

- Type hace referencia a qué tipo de rama es. Los diferentes tipos son “epic”, si es una épica, “feature” para las nuevas funcionalidades, “fix” para arreglos o “hotfix” en caso de que los arreglos sean directamente a develop o master. En principio, los tests se incluirán en la misma rama de feature a cargo de una persona distinta a la que realiza el código de la feature.
- Name es el nombre de la tarea correspondiente. Debe ir escrito en kebab-case (minúsculas separadas con guiones).
- Se incluirá al final el número identificador de la issue de github de la siguiente manera: “/7”
Ejemplo: si tengo que hacer la tarea con identificador en github #2 sobre listar usuarios, de la épica “Gestión de usuarios”, tendríamos las siguientes ramas:
-
epic/user-management
-
feature/list-users/2
Procedimientos de Revisión de Código
Con el fin de llevar un control del estado de las nuevas características que se incorporan en el sistema, se plantea un procedimiento a seguir por parte de cada uno de los integrantes del equipo una vez se haya considerado completado el desarrollo asociado a una rama de feature.
Un aspecto fundamental, pero que merece la pena mencionar, es que todo cambio que se efectúe en el repositorio de trabajo no podrá incumplir ninguno de los tests integrados.
- Se realizarán los tests correspondientes de la característica en la misma rama del desarrollo. Una vez se hayan desarrollado todos los tests necesarios y el sistema los pase, se podrá continuar al siguiente punto.
- Se procederá a solicitar una pull-request hacia la rama de la épica a la que pertenezca o develop, rellenando la plantilla. Dos integrantes del equipo de desarrollo relacionados con esa característica deberán revisar esa solicitud. Además, para concluir la revisión, la pull-request debe obtener un resultado positivo en la inspección de código de codacy.
- Una vez aceptada e integrada la pull-request en develop, y a no ser que se diga lo contrario por parte de los coordinadores de los equipos, se eliminará la rama de desarrollo de esa feature.
- Por último, para volcar los cambios de develop en master, al menos tres miembros del equipo deberán revisar los cambios efectuados, a fin de garantizar la estabilidad del código. Esto deberá llevarse a cabo con cada funcionalidad, fomentando así el desarrollo ágil del proyecto.
Patrones de Commit y Pull-Request
Cada commit deberá indicar el tipo de cambio aplicado, siendo este atómico, de tal forma que de un simple vistazo cualquier integrante del equipo pueda conocer su naturaleza. Por ello tendremos commit de diferentes tipos siguiendo el patrón de convencional commits.

Los tipos son:
- feat: se refiere a una nueva característica del sistema.
- test: el código es de pruebas de una característica del sistema. (aplicable en casos excepcionales donde no se haya realizado testing en la rama de feature)
- fix: arregla una funcionalidad, bug, etc.
- config: modifica el código de los archivos de configuración.
- refact: se realiza una alteración del código con el objetivo de aumentar la calidad de este.
Luego, proporcionar una breve descripción que aporte la idea fundamental del cambio y la id correspondiente de la tarea en el tablero del proyecto. Por último, las secciones body y footer son opcionales, a rellenar exclusivamente cuando haya que aclarar algo o alertar especial cuidado por cambios que hagan al sistema incompatible con versiones anteriores.
Por otra parte, para facilitar la tarea del desarrollador, se creará una plantilla a rellenar para las pull-request del repositorio remoto. Esta plantilla tendrá la siguiente información:
- Título o descripción que aporte una idea clara acerca de los cambios que incluye.
- Referencias a las issues que contiene.
- Una descripción de los cambios propuestos en la pull-request.
- Mención de las personas del equipo responsables de haber desarrollado y revisado dichos cambios.
Políticas de Integración Continua y Despliegue Continuo
Con el fin de facilitar la tarea de agregar y revisar nuevas características al sistema, se plantea un sistema de rutinas automáticas en el repositorio remoto empleando GitHub Actions. Estas rutinas se ejecutarán cada vez que se cumplan ciertas condiciones en el repositorio. En principio, implementaremos tres rutinas.
La primera, denominada backend, consistirá en una rutina que se ejecutará siempre que haya un push en las ramas develop o master y ejecutará los siguientes pasos para las versiones de Python y PostgreSQL del proyecto:
- Realizará un clonado de la versión del proyecto con los últimos cambios que lanzaron el action en la rama.
- Instalará todas las dependencias y configurará el proyecto para su lanzamiento.
- Ejecuta todas las migraciones del proyecto a la base de datos de PostgreSQL.
- Ejecuta todos los tests del sistema, comprobando que todos ellos pasen sin errores.
- Ejecuta el análisis de cobertura de Codacy.
La segunda, denominada frontend, no es más que una réplica de la rutina anterior, solo que con ciertas modificaciones para adaptarla a las tecnologías de esta sección del sistema. Se ejecutará siempre que haya nuevos cambios en las ramas develop o master y ejecutará los siguientes pasos para las versiones de JavaScript, TypeScript y Angular del proyecto:
- Realizará un clonado de la versión del proyecto con los últimos cambios que lanzaron el action en la rama.
- Instalará todas las dependencias y configurará el proyecto para su lanzamiento.
- Ejecuta todos los tests del sistema, comprobando que todos ellos pasen sin errores.
- Ejecuta el análisis de cobertura de Codacy.
Por último, la tercera rutina, denominada deploy, consistirá en la automatización del proceso de despliegue del sistema. Se ejecutará cada vez que se hayan pusheado nuevos cambios en la rama master y la ejecución de las rutinas frontend y backend resulten como positivas. Realizará los pasos necesarios para desplegar automáticamente en Google Cloud.
En el caso de que alguna de las rutinas resuelva con una etiqueta fallida, el integrante responsable de subir los cambios que ejecutaron la rutina debe notificar a sus compañeros mediante la creación de una issue de fix/bug.
Herramientas de Gestión de la Configuración
En esta sección, se describen las diferentes herramientas empleadas por la organización para llevar a cabo el desarrollo de manera ordenada y limpia, asegurando una gestión controlada de los cambios del producto en todas sus fases.
Primero, para llevar a cabo una gestión controlada de los cambios del código fuente, así como una organización entre los integrantes del equipo de desarrollo de la organización, se utilizará GitHub, el sistema de control de versiones por excelencia. Además, esta herramienta cuenta con funcionalidades de personalización y automatización, como plantillas para las issues y las pull-requests, o rutinas de entornos virtuales, respectivamente.
Segundo, con el fin de mantener al equipo completamente comunicado, se empleará Discord, servicio de mensajería instantánea y chat de voz VolP. En esta plataforma, los usuarios tienen la capacidad de comunicarse por llamadas de voz, videollamadas, mensajes de texto, o con archivos y contenido multimedia en conversaciones privadas o como parte de comunidades llamadas servidores. No obstante, aquellas comunicaciones relevantes durante los sprints deberán ser llevadas a cabo en los comentarios de las issues de GitHub o en las propias Discussions para que todo el equipo pueda recibir la información relevante.
Tercero, buscando crear una base de conocimiento común para el equipo y la organización, y tras estudiar las diferentes soluciones en línea disponibles, se ha decidido utilizar la herramienta Confluence, software de colaboración en equipo. Permite desarrollar la documentación de un sistema u organización desde diferentes puntos de vista (estratégico, marketing, técnico, …) y facilita la búsqueda de dicha información gracias a filtrados en base a términos y etiquetas. Además, cuenta con una gran diversidad de plantillas que dinamizan el desarrollo de la documentación.
Por último, para asegurar y desarrollar ciertas secciones de la documentación del proyecto que posteriormente deberán ser entradas al cliente, se utilizará OneDrive, sistema distribuido de almacenamiento que permite crear carpetas de colaboración entre diferentes personas, ayudando a la organización en el proceso de redacción y maquetado de los documentos.
Cuenta con la suite de Microsoft Office, por lo que se podrán desarrollar desde documentos de texto y celdas de cálculo hasta imágenes y presentaciones.
Plan de Respuesta ante Incidentes
El objetivo de este plan es establecer un proceso claro y eficiente para la gestión de las incidencias que se puedan producir en la aplicación AparKing. Este plan busca minimizar el tiempo de respuesta y resolución de las incidencias, así como mejorar la experiencia del usuario.
Las incidencias podrán ser recibidas por los siguientes canales:
- Datos de contacto a través de la propia aplicación: Dentro de la aplicación se ofrecerá un apartado con nuestros métodos de contacto, tal y como el correo electrónico, por donde se podrán recibir las posibles incidencias que sufran los usuarios.
- Redes sociales: Nuestro proyecto dispone de una cuenta de Instagram con la que se podrá monitorear las incidencias recibidas con mensajes privados de los usuarios.
Una vez recibida una incidencia, se consultará con el resto del equipo si, según su severidad y urgencia, requiere abrir una issue de arreglo dentro del tablero del proyecto. En caso afirmativo, se seguirá el patrón de creación de issue tipo “fix” para solventar el problema.
Una vez cerrada la issue, se comunicará al usuario el nuevo estado de la incidencia y, si se confirma que no supone un problema para dicho usuario, se cerrará dicha incidencia del registro.
Asimismo, las incidencias más comunes se registrarán en nuestra base de conocimiento para su revisión. Por el momento, no se valora la creación de un sistema de gestión de tickets para las incidencias.
Documentación y Conocimiento
La documentación del código es fundamental para comprender el funcionamiento de este y facilitar su mantenimiento. En nuestro caso, haremos uso especialmente de Python para el backend y, por ende, sería positivo incluir comentarios antes de cada función para explicar su uso, parámetros y otros detalles. Aquí podemos ver un ejemplo:
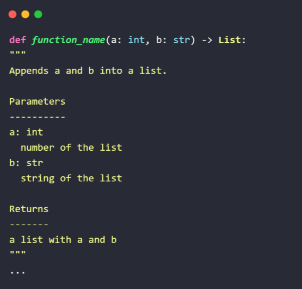
En principio, se explicará primero la función del código seguido de los parámetros que recibe y, posteriormente, lo que devuelva dicha función. Tras esto, se pueden añadir opcionalmente más detalles si fuese necesario.
Por supuesto, si hay que añadir comentarios o documentación en Angular, se deberá seguir las mismas pautas que en Python adaptándose a dicho entorno.
Por otro lado, la documentación del sistema debe proporcionar una visión general del mismo, incluyendo su arquitectura, componentes, funcionalidades y casos de uso. Se recomienda estructurar la documentación del sistema de la siguiente manera:
- Introducción: Descripción general del sistema, incluyendo su objetivo, alcance y público objetivo.
- Arquitectura: Descripción de la arquitectura del sistema, incluyendo sus componentes y cómo interactúan entre sí.
- Componentes: Descripción detallada de cada componente del sistema, incluyendo su funcionalidad, interfaces y configuración.
- Funcionalidades: Descripción de las funcionalidades del sistema, incluyendo los pasos necesarios para realizar cada una de ellas.
- Casos de uso: Descripción de los casos de uso del sistema, incluyendo los diferentes escenarios en los que se puede utilizar el sistema.
Asimismo, para la base de conocimientos general, se empleará Docusaurus en colaboración con el resto de los grupos. Ahí, por ejemplo, se almacenarán los reportes de uso de Inteligencia Artificial.